

Doubling our monorepo’s deployment rate with Gitlab Merge Trains
by Amédée d'Aboville & Jimmy Berry
This is the story of how we averted a scaling crisis in our merging and deployment process using Gitlab Merge Trains.
Over 2021 a lot of things changed for Outschool: We moved from Heroku to AWS+CDK, our build+deploy time slowly increased from 20 minutes to 30 minutes, and our team grew from 20 to 50 engineers. This meant our merge velocity increased, but on an average day we could still only deploy ~20 times within work hours across time zones.
At the time we used a Slack channel to coordinate our deployments (it started as an informal queue and was later upgraded to a queue chat bot. When first implemented, the queue had ~3-4 people in it on average, but as we grew it averaged 6-8 people (incurring 3 hours of wait) and could reach up to 12. We thought we could finish larger projects to speed up our CI before our growth caught up to us, but our deployment queue clogged up before we could fix it.
How many deployments per day can you do with a single queue?
In a serialized deployment queue, it turns out you need to have 4-5x the capacity to keep the waiting time low. The waiting time depends on the utilization (the fraction of time someone is deploying) and arrival variability (if everybody holds their changes before a long weekend and then piles them in on Monday):1
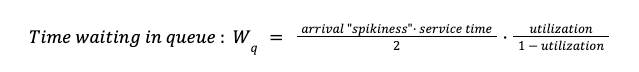
Keeping the spikiness and the deploy time constant, here’s the waiting time vs utilization:

As utilization goes to 100%, waiting time goes to infinity. For this reason, you don’t want to run your application servers, or any other queueing system, at 90% utilization. All queuing systems (CI queues, grocery stores, microprocessors, teams, etc) need slack in them to keep response times low because response times go to infinity as utilization increases (although in the real-world things break down a little bit before infinity).
Our average utilization was ok, but our “spikiness factor” was quite high so out of nowhere we had several full queue days in a row. Even if the preceding days had seen no merges, the queue could fill up in the early morning, and you’d have to wait all day if you even managed to merge. Engineers would wake up at 6am to secure their place in the line, then go back to bed 😰. It was terrible, and it was because our arrival variability was so high.
Our long term projects to optimize our CI and break apart the main app into independent services were still a ways out. We had started a second, independent queue that a few devs working on a different app could use, but it wasn’t enough, and we needed something ASAP. We considered alternatives like batching releases into a handful a day 😢 and beefing up our CI runners, but those alternatives either had huge costs or limitted benefits and so in the end we chose Merge Trains.
What’s a Merge Train?
Merge trains automate the process of queueing and merging code changes for you. Gitlab’s own explanation is here, but in short, it runs CI jobs in parallel for the whole queue. Whenever the first pipeline completes, the MR is merged, and so on. If a pipeline fails, the associated MR is kicked from the train and all preceding pipelines are restarted.

This greatly increases your deploy capacity by running the build+test steps of your deployment process in parallel. For example if it takes 30 minutes to build a docker container and run tests, but only 10 minutes to deploy the container to AWS, you can run the build steps in parallel, and the deploy step becomes the bottleneck, letting you theoretically merge 6 times per hour instead of 1.5.
Did it work?

You bet! The day after we enabled merge trains we hit a record 35 merges after hovering around 20 and struggling the month before. We now average 30 without breaking a sweat, and recently peaked at 45 on a normal day.
For developers the process was simplified from:
- Join Slack queue
- Wait and watch to become first
- Press merge
To just pressing this button:

Instead of having queue spikes take an entire day to clear or carry over into future days to be combined with the additions from that day, the speed boost from running CI concurrently and automatically merging afterwardsthe concurrent nature of the merge train combined with the resulting merges in rapid succession effectively clears spikes. Our worst merge spikes looked something like this:
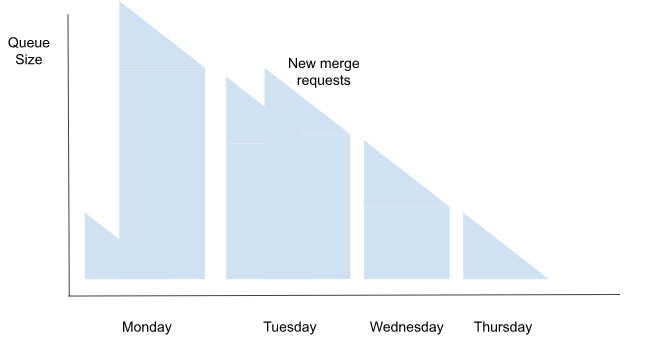
After merge trains the queue looked like this:
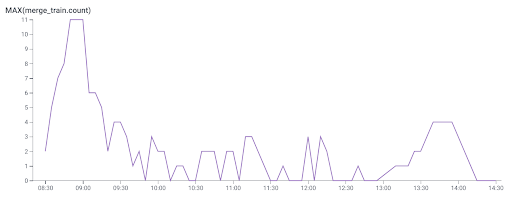
The significant build up at the beginning of the day was completely dissipated by two large batch merges. All day deployment activity happened without a large wait, regardless of the queue size.
We can estimate the theoretical new upper limit. A full build in a merge train pipeline takes ~30 minutes, and the merge train can run up to 20 concurrent pipelines. If they all succeed and merge in a batch, that would translate to 400 merges in a 10 hour window (working across time zones). Using the same numbers, our old deployment process could only handle 20 merges per day, assuming zero human delay between deployments (which never happened).
Considering the size of the change, the rollout was pretty smooth, but we hit a few speed bumps and we’re still ironing out kinks. There were things we had to fix in our system as well as bugs in Gitlab that got in the way once we enabled it 2.
Flakiness slows down the train
Since any train pipeline failure prevents a merge and restarts all subsequent MRs, the impact of flakiness and transient errors becomes strikingly more noticeable. Prior to merge trains, failures caused by flakiness could be easily ignored by simply merging an MR. After enabling merge trains a particularly flaky test could bring the train to a near standstill as it would grow and the restarts consume more CI resources. Each set of restarts re-rolls the dice on the flaky test: a MR pipeline that previously passed might fail and trigger even more restarts.
Overall this has been great for our team, since it forces us to deal with flaky tests promptly, and we’ve fixed all of the ones that came up. With our old process it was too easy to let tests go flaky.
Lack of visibility
It’s hard to believe, but Gitlab released this whole complex feature without a page to show you the status of the train. You can cobble together a search in the pipelines page with 3 different filters, but by default it’s out of order and it’s really unclear. We quickly used Gitlab’s API to build a subcommand on our internal CLI tool to visualize the deployment queue:
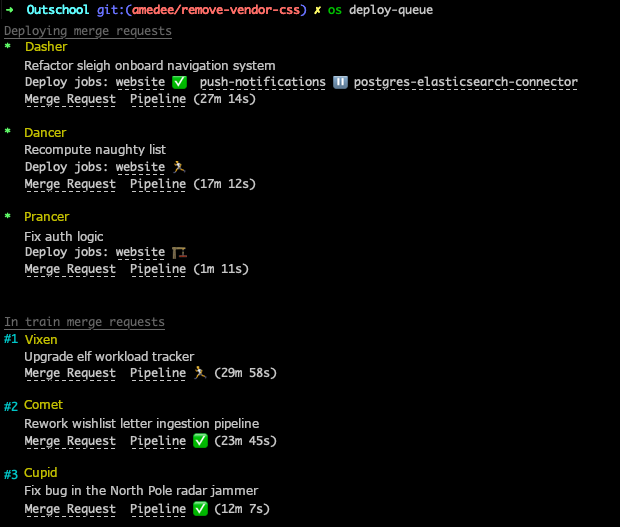
We hope eventually Gitlab will offer a page like this to everyone.
Conclusion
Serialized deploy queues managed by chatbots work for a long time, until they don’t. You need 4-5x the theoretical capacity of your actual deployments/day to keep the system snappy. At the point where the chatbot queue stopped scaling for us, merge trains came in really handy to greatly increase our capacity. We’re still working to improve the speed3 and reliability of our CI jobs, since a large train can still feel sluggish. Overall, our developers love Merge Trains since they don’t have to queue up manually and they can merge faster and more often.
Footnotes
-
This is based off the Marchal(1976) approximation for a G/G/1 queue (mentioned here Here) with the variance of the service time to 0. The “arrival spikiness factor” is the square of the Coefficient of Variation of arrivals. ↩︎
-
To be specific, we hit #352581, !8326, #207187 and #27117 and are working on submitting a fix for #362844. ↩︎
-
Having the same SHA be present in the merge train pipeline would allow for cleanly reusing container builds. See !207187. ↩︎
About the Author

Amédée d'Aboville
Amédée is a software engineer on the Platform team at Outschool.
Jimmy Berry
Software Engineer on the Infrastructure team at Outschool.