

Heroku Exodus and Gitlab Migration
by Jimmy Berry
This article will cover our migrations from Github to Gitlab and our exodus from Heroku to AWS. The motivating factors for taking on such a move will be reviewed along with the high-level approach and some specific implementation details that kept the process smooth.
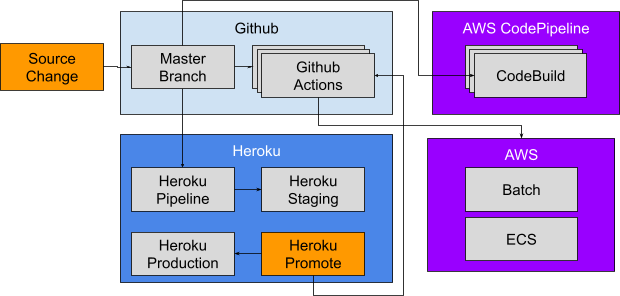
While using Heroku as our primary hosting platform we encountered hurdles which could not be easily surmounted. One of the first hurdles encountered was the lack of flexibility in the periodicities provided by the Heroku Scheduler in addition to the need to execute workloads in several language environments from a single repository. After a consensus was reached, batch jobs started to be developed and deployed to AWS. When AWS Batch proved to be successful, all existing jobs were migrated from Heroku Scheduler. This was the first in a series of hurdles that motivated us to move our infrastructure away from Heroku.
Goals
A few of the high level goals motivating the migration were as follows.
- Flexibility: pertaining to builds and deploying multiple applications from one repository.
- Cost: cheaper resource costs due to direct management.
- Convenience: not everything could be deployed to Heroku so moving the rest keeps everything together in one place.
- Control: more knobs to tune which provide a higher degree of control.
In parallel to this project, we were considering some security tooling and CI goals which overlapped since certain approaches had the potential to provide solutions to those goals as well.
All of the above needed to be achieved with minimal development disruption and workflow change. Although a consensus had been reached in regards to the goal, the means of migrating the primary website and development workflow remained unclear.
Direction
After evaluating our current workflow and usage of Heroku, the following core requirements stood out as needing to be replaced:
- Website hosting environment: load balancer and application servers
- Database: Postgres
- Background jobs
- Secrets: source of truth and propagation to various environments
- Environments
- Release workflow: deployment, overview, and rollback
- Review apps: integration with SCM and CI along with life-cycle management
- Metrics: high-level resource and response metrics
This list is not exhaustive, but these are the primary items that needed to be replicated to avoid a regression in our core development workflow and application hosting. Of them, we had already migrated the database to AWS and switched to using AWS Batch for scheduled workloads before expanding the scope to the list above.
We evaluated a number of options and approaches before settling on a general direction. From there we prototyped an approximation of our workflow using Gitlab and a prototype deployment of our website on ECS. After verifying that the prototypes demonstrated the approach would work we spent time building consensus around the approach through various internal engineering guilds and our all engineering design review. After a few weeks we had general agreement on the direction.
Website hosting environment
To replace Heroku’s hosting environment we ended up selecting ECS Fargate in part because we already had a few internal and smaller services running there and thus familiarity. Building a container with the source and dependencies was relatively straightforward. Deploying multiple identical tasks to ECS is as easy as changing a number and positioning an ALB in-front of the ECS tasks, and makes for a rather compelling setup.
Database
The primary Postgres database was migrated to AWS RDS while the website and some background jobs remained in Heroku. The migration was practiced until perfected with a series of scripts. During a scheduled down-time the final migration and cut-over was performed as had been rehearsed.
Background jobs
A variety of background jobs which had run in the Heroku Scheduler were migrated to AWS Batch backed by a Fargate cluster. By building some CDK infrastructure the definition of such jobs, and their porting, was made relatively simple.
Secrets
The existing approach was to use Heroku config vars as the source of truth for secrets. The config vars are presented to a Heroku application at run-time as environment variables. The same workflow was provided to AWS Batch jobs by generating AWS Secrets, which are then bound at run-time, from the Heroku config for each environment. Each Heroku review app has corresponding config vars which are then used to generate an AWS Secret from a Heroku release script.
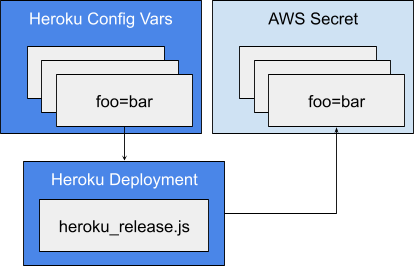
Although Gitlab CI variables can fill the role of Heroku config vars we ultimately decided to switch over to AWS Secrets as the source of truth. Gitlab does provide audit events for CI variable changes and the scope field does allow for patterns, like review/*, which can be used to set defaults for all review environments, but since everything ends up as AWS Secrets it simplified things to use that as the source of truth for run-time secrets. Obviously, for CI secrets Gitlab CI variables are the way to go.
To keep a Heroku-style workflow and simplify some of the workflow bits, we added a config subcommand to our CLI. The command wraps setting the AWS secrets and restarting services as needed. This simplifies the developer workflow by allowing for pushing a branch, creating a merge request to trigger the CI deploy of a review app, and running config commands from the same branch locally to change secrets. For production, running the config command is all that is needed to apply a secret change since the service restart is triggered automatically.
Environments
Heroku provides an overview of an application and its deployment history. Having some sort of high-level way to see what is running is important in a large team. Heroku had been at the center of our workflow with external environments not having any such overview. Using Heroku pipelines we had been promoting a staging build to production through a button in the web interface.
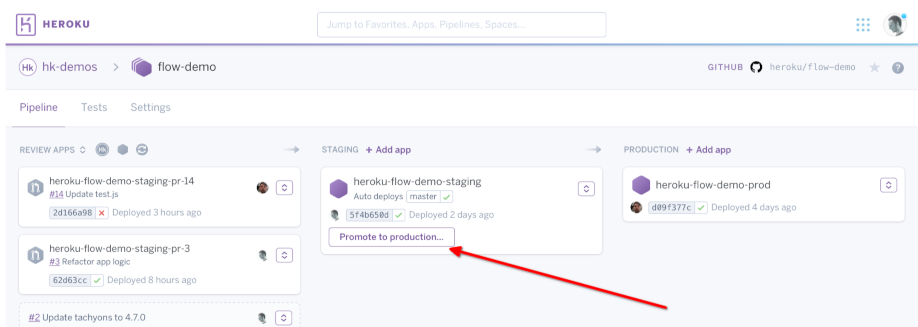
Gitlab can replicate the high-level overview bits in addition to life-cycle management and review app integration through environments and deployments. One can see all environments associated with a project, each environment’s deployment history, and start a rollback to a deployment from the history. This fulfilled the high-level overview requirement in addition to providing an audit log for who was triggering deployments, and deployment tooling logs via CI output.
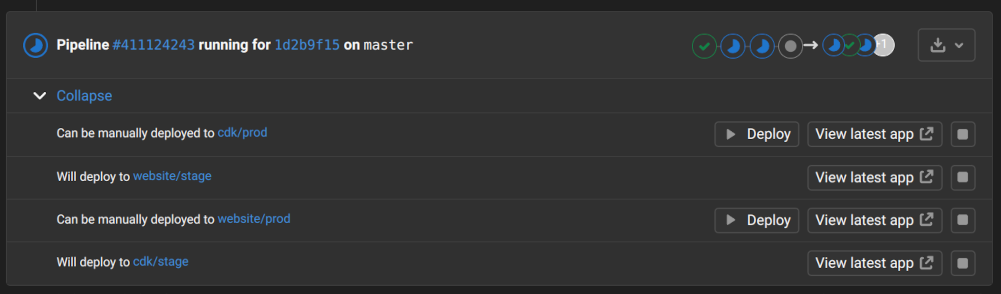
Gitlab CI jobs can be mapped to environments such that running the job constitutes a deployment to that environment. Having deployments be performed in the CI tool makes it easy to have them be conditional (ex. on tests passing) or depend on prior steps (ex. container building). Gitlab environments may also be defined with a stop job that can be used to teardown the environment. The stop job can be triggered manually, or automatically by an associated MR being closed/merged, or even by an expiration timeout. Deploying review environments attached to an MR in this way makes cleanup of those environments automatic.
Gitlab also provides some UI conveniences that go a long way towards simplifying the developer experience beyond what was possible with Heroku. All of the environments associated with the changes in a merge request are enumerated in the Gitlab MR UI along with a simplified indication of their state. When combined with manually triggered deployment jobs a Deploy button is presented that we use to trigger production deployment without ever leaving one’s merge request. This workflow works for all of the environments affected by an MR.
Metrics
Heroku was used to observe and alarm on a variety of high-level website resource usage conditions and overall request responses. These metrics were replicated in AWS Cloudwatch and Honeycomb to provide equivalents.
Migration
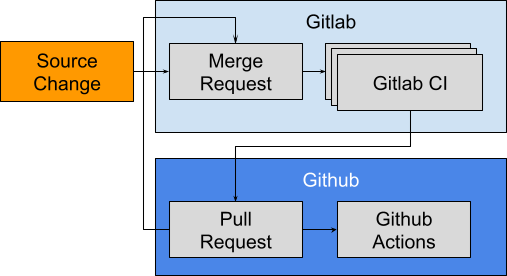
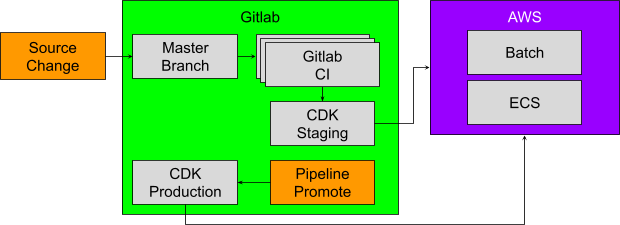
In order to achieve the goal of moving from Heroku to AWS through the enabling migration from Github to Gitlab we decided an all-or-nothing style migration was unlikely to be practical. Rather, we utilized an incremental approach with an initial source cut-over to Gitlab. In order to minimize intermediate change and thereby minimize risk of breakage along with reduced workload we settled upon mirroring changes made in Gitlab to Github. After we completed the migration to Gitlab we resumed the migration from Heroku to AWS.
A full import of the Github project was made on Gitlab after which all source changes and reviews were made on Gitlab. As part of the CI process on Gitlab changes were mirrored to Github which would then trigger integrations and CI the same as before the cut-over.
Mirroring
A mirror job pushed review branches from GL to GH and generated a GH pull request. Upon completion the variable GITHUB_PR was exported via a dotenv artifact. The GL environment URL is then set to provide easy access to the mirrored PR which contained the GH Actions status checks (ie. click “View latest app” for the mirror environment to navigate to GH PR). The dotenv file was also cached to make it easier to tell if a PR had already been created without requiring an API call.
.gitlab-ci.yml
mirror:review:
script:
- ./ci/mirror.sh
- ./ci/github_pull_request.sh
artifacts:
reports:
dotenv: deploy.env
cache:
key: mirror-review-$CI_COMMIT_REF_SLUG
paths: [ deploy.env ]
environment:
name: mirror/$CI_COMMIT_REF_SLUG
url: https://github.com/$GITHUB_REPO/pull/$GITHUB_PR
on_stop: mirror:review:stop
./ci/github_pull_request.sh
#!/bin/sh
JSON="$( jq -n '{
title: "[GITLAB] \(env.CI_MERGE_REQUEST_TITLE)",
head: env.GITHUB_BRANCH_MIRROR,
base: env.GITHUB_BRANCH_BASE,
body: "See \(env.CI_MERGE_REQUEST_PROJECT_URL)/-/merge_requests/\(env.CI_MERGE_REQUEST_IID)."
}' )"
curl -s \
-H "Accept: application/vnd.github.v3+json" \
-u "$GITHUB_PR_USER:$GITHUB_PR_TOKEN" \
"https://api.github.com/repos/$GITHUB_REPO/pulls" \
-d "$JSON" \
> curl.out
NUMBER="$(jq '.number' curl.out)"
if [ "$NUMBER" != "null" ] ; then
echo "Created PR #$NUMBER...storing PR number."
echo "GITHUB_PR=$NUMBER" > deploy.env
elif jq '.errors[0].message' curl.out | grep -qv "\"A pull request already exists" ; then
cat curl.out
echo "$JSON"
exit 1
else
echo "PR already exists...using cached PR number."
fi
./ci/mirror.sh
#!/bin/sh
mkdir -p ~/.ssh
echo "$MIRROR_KEY" > ~/.ssh/id_rsa
chmod 600 ~/.ssh/id_rsa
export GIT_SSH_COMMAND="ssh -i ~/.ssh/id_rsa -o StrictHostKeyChecking=no -l git"
git remote add mirror "$MIRROR_URL"
git remote -v
source="HEAD"
if [ ! -z ${MIRROR_DELETE+x} ] ; then
source=""
fi
git_opts=""
if [ ! -z ${MIRROR_FORCE+x} ] ; then
git_opts="--force"
fi
git push $git_opts mirror "$source:refs/heads/$MIRROR_BRANCH"
The mirror:review:stop job deleted the branch from GH which automatically closed any related PR.
The existing Heroku integration, which provided review apps and automatic deployment to staging on merge to the default branch, remained unchanged. On the Gitlab side a NOOP CI job was created to translate the mirrored GH PR number into a Heroku review app URL exported as a GL environment.
web:review:
stage: deploy
image: ${CI_DEPENDENCY_PROXY_GROUP_IMAGE_PREFIX}/busybox
script:
- echo noop
needs:
- "mirror:review"
environment:
name: web-review/$CI_COMMIT_REF_SLUG
url: https://example-staging-pr-$GITHUB_PR.herokuapp.com/
on_stop: web:review:stop
The purpose of the environments was to provide quick access for developers on their GL merge requests to both the GH PR and Heroku review app associated with the changes. Given GL environments handle life-cycle events the mirroring setup manages itself. When an MR is merged or closed (or stopped via auto_stop_in) the associated environments are stopped which in this case deletes the remote branch which causes the GH PR to be closed and the Heroku review app to be destroyed.
CI Port
After the initial cut-over and mirroring setup was completed, the Github Actions workflows were ported to Gitlab CI incrementally. Merge requests would both drop the Github Actions and add the new Gitlab CI definitions which allowed for seamless incremental change. From a developer perspective more and more results were provided directly in their Gitlab merge request and there was less reason to visit the GH PR.
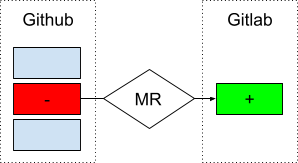
For the most part Gitlab CI encompasses Github Actions functionality, but there are differences in the general approach that can make porting a bit more involved. During our porting efforts the general idea was to change as little as possible, but a few liberties were taken to make use of some unique Gitlab features.
One of the major differences was in porting AWS CodePipeline to Gitlab CI and enhancing our sub-service CI/CD to make heavy use of Gitlab’s child-pipelines. A Gitlab pipeline is a collection of jobs, a map of variables, and an associated git hash. Essentially, a child pipeline is a pipeline associated with a parent that can have a different map of variables and jobs. The child pipeline can be defined dynamically as the output from a job on the parent pipeline.
Using the dynamic ability of child pipelines we were able to add a custom synthesizer to our existing CDK defined CodePipeline to generate Gitlab CI jobs instead. This avoided the need to rework those stacks while allowing the execution to be migrated into Gitlab. Having everything running in Gitlab improved developer visibility and allowed for other jobs to depend on those jobs completing without regressing to polling an API in a CI job.
Dynamic child pipelines also allowed us to apply the same CI job template to a number of directories within the code-base and allow any combination of them to be run given the changes present in a merge request. This flexibility avoided the need for lots of duplication or monolithic CI jobs. Instead we end up with dynamically generated jobs sized as one would desire.
An optimization we made was to build a custom CI container image, pushed to Gitlab’s container registry, that contains a variety of commonly required dependencies to avoid having to install them every time those CI jobs run. Instead the container is pulled which can also be cached on the runners.
Any ported deployment jobs were given environment metadata to allow for the deployments to be managed in Gitlab. This also makes it possible to decipher the effect of merging by the environments that it touches.
Self-hosted CI runners
One of the general problems with CI is that things tend to grow slower over time. That had certainly been the case with our CI and we had made large refactoring and optimization efforts to improve the performance. That said, larger machines tend to be cheaper than refactoring. With our migration we decided to run our own Gitlab CI runners to improve the performance of our CI pipeline and knock down the time required for a few beefy jobs.
There are a variety of options for self-hosting, but we settled on the Terraform module npalm/gitlab-runner/aws due to ease of setup, auto-scaling, and running on AWS. Using the setup we can optimize the instance size and volumes to our workloads. Using Gitlab job tags, jobs can be routed to either the default shared runners or specific groups of self-hosted runners. All of our heavy main CI jobs then are routed to our more beefy CI runners.
Monitoring
Our application level instrumentation via Honeycomb transitioned with us to the new hosting platform. The instrumentation was utilized to set up a dashboard to provide direct comparisons between processes running on Heroku vs those running on Fargate. The comparisons made it easy to spot differences in performance and caught a setup issue early during load testing. Beyond that, AWS Cloudwatch provides a variety of system level metrics useful for troubleshooting resource limitations.
Website hosting port
After all the prerequisite bits were in-place work began on fleshing out the primary website build and deploy process to target Fargate. Having several secondary services already on ECS, we were familiar with the requirements and workflow surrounding ECS, but needed to extend some of our tooling to handle the more extensive needs of the main website.
Building a container image was relatively straightforward atop the upstream node image. The process was roughly: copy code, install dependencies, and set environment variables for context. The image is built in Gitlab CI and pushed to ECR as our existing production images were in ECR.
Deployment is performed via AWS CDK using some infrastructure to provide a relatively simple interface to a deployable unit. Essentially, the deployable enumerates the bits that need to be available for the application to function. The following is an example of the resulting deployable format.
{
environment: {
APP_HOSTNAME: "review.example.com",
IS_REVIEW_APP: true
},
replicaServices: {
Website: {
component: Component.Website,
appEnvSecrets: true,
numCpus: 4,
memoryMb: 2 * 1024,
desiredCount: 2,
deploymentScaleType:
mode === "review" ? "FewerThenDesired" : "MoreThenDesired",
loadBalancer: {
containerPort: 3000,
healthCheckPath: "/.well-known/health-check",
domainName,
publiclyAccessible: true
}
}
}
}
From there a deployment job runs after the image is pushed to ECR which makes a deployment to the relevant environment from Gitlab. CDK provides outputs (similar to Terraform) which we use to expose the deployed URL as a dynamic variable for the Gitlab environment metadata. Rolling back is accomplished by re-running a prior deployment job which can be done easily through Gitlab environment history.
This definition is used to generate an ECS service deployed behind an AWS ALB. We ended up using a set of pre-prod ALBs for staging and review apps with a separate production ALB to avoid creating an ALB for every review app.
Tuning
Our production Heroku dynos provided 8 vCPUs, but ECS Fargate has specific increments of available task sizes with the largest providing 4 vCPUs. Given 4 is half of 8 we started with twice the number of ECS tasks compared to the number of Heroku dynos we were using. After some load testing we determined that the ECS performance was comparable if not a bit better than our Heroku performance given the same total of vCPUs and RAM, but a different node count and size.
Any remaining confidence would be gained during the gradual production cut-over.
Cut-over
For the final cut-over we decided to take advantage of Cloudflare load balancers. Given Cloudflare was already proxying traffic to our Heroku application, switching to a load balancer was almost instantaneous and seamless for the end user. Two origin pools were configured, one with all traffic sent to Heroku and the other with a configurable split between AWS and Heroku. During the lead up to the cut-over and during the transition itself we deployed to both Heroku and AWS for review apps, staging, and production to ensure we could always drop back if anything went awry.
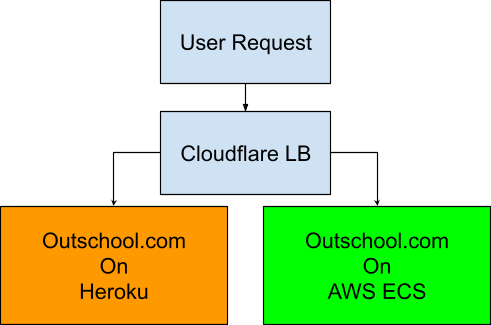
After testing the process on our staging environment, the load balancer was rolled into production with the Heroku pool given priority. Once we verified that everything continued working correctly, we switched to the split pool and dialed things up. Over the course of a few days all traffic was eventually sent to the AWS origin. After a week we deployed an empty application to Heroku to ensure no dependencies remained and stopped further deployments to Heroku. Later we tore down the Heroku application completely.
Post Migration
We have since increased the number of nodes in our production ECS deployment to tune the event loop latency which would not have been cost-effective on Heroku. Work began to refactor our main application into smaller chunks that can be reused in separate services which was not possible under the build constraints imposed by Heroku.
Workflow
The developer workflow changed from:
- Push branch to Github
- Create pull request on Github
- Merge pull request on Github
- Promote on Heroku
To:
- Push branch to Gitlab
- Create merge request on Gitlab
- Merge merge request on Gitlab
- Promote on Gitlab
Overall, the general workflow was kept largely the same, while the underlying tooling and processes changed significantly. The reduction in the number of underlying tools makes debugging a failure, or even knowing where to find a failure, simpler and requires less cognitive overhead. A developer never has to leave their merge request to merge, monitor master pipeline, and promote to production. Gitlab integrates all the artifacts produced during the CI pipeline along actions that can be taken into the merge request.
Bonus
Outside of achieving our primary goals there were a few improvements gained along the way that are worth noting.
Integrating with Gitlab’s test report not only provides a summary of test results, but also tracks changes to the tests reported and the test state. This is most notable when a failure is introduced into the target branch which Gitlab highlights when the failure occurs on a merge request. The highlight helps avoid wasted developer time or repeated discussion threads.
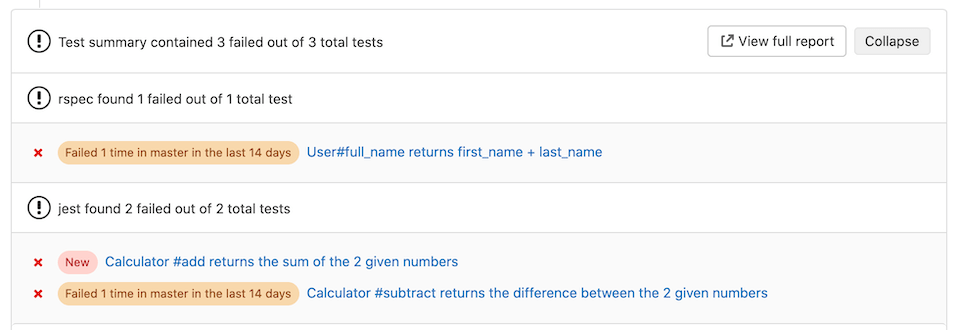
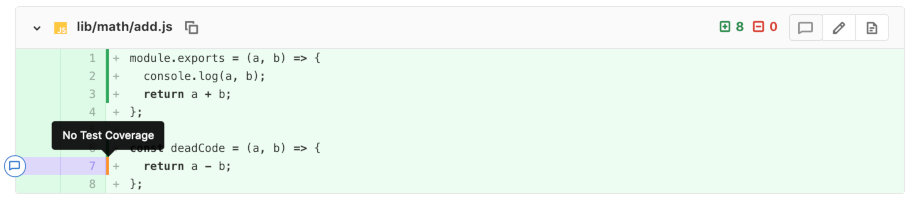
Similarly, code coverage data can also be integrated into the merge request interface and shown in the diff. This makes for a straightforward experience for checking for test coverage of new code.
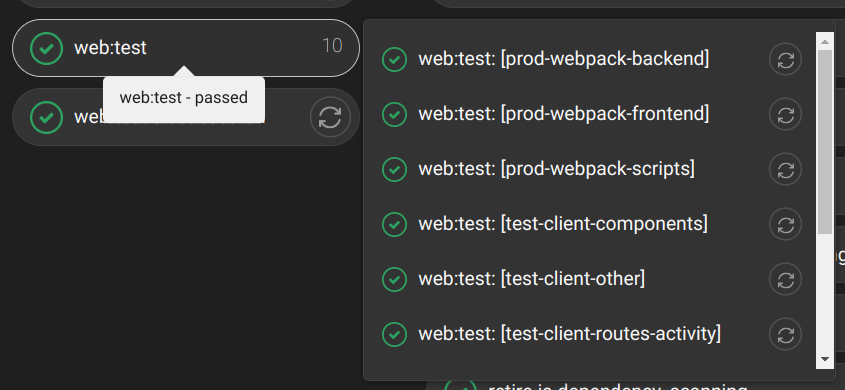
An annoyance we had with Github Actions was the inability to retry individual matrix jobs. Gitlab supports retrying any job individually regardless of being defined as part of a matrix.
Triggering chunks of CI based on changed file paths is rather common, but when combined with the ability to place CI definitions alongside the relevant code makes it very clean to include changes to the CI definition in the trigger. Otherwise, one generally has to list the defining file as a special case in the changes path filter.
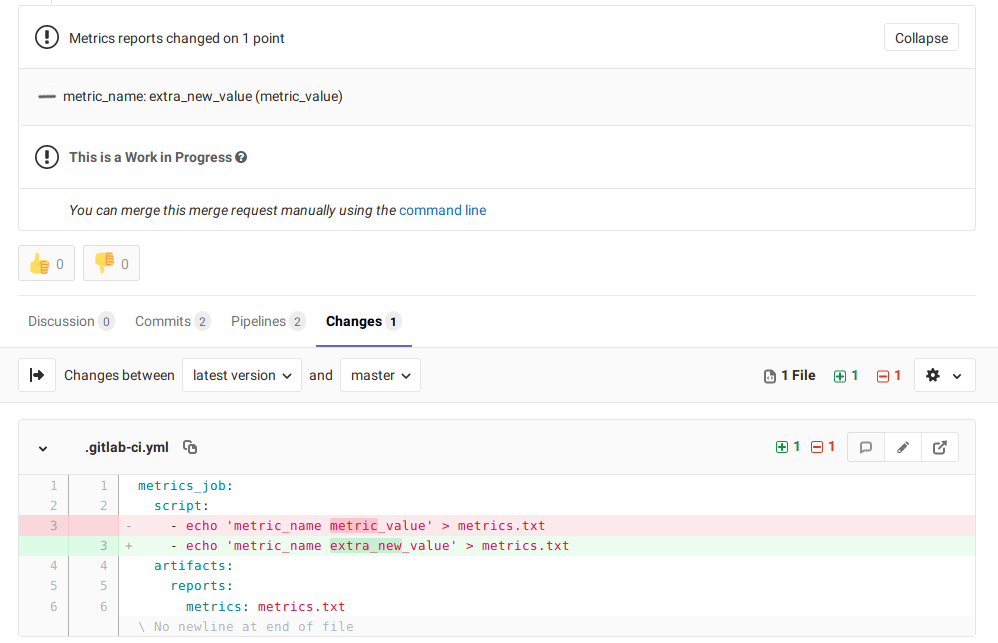
As is common, we have a few CI jobs that essentially dictate the pace of CI by being the longest to complete and yet vital to the workflow. Gitlab provides a metrics report that can be used to track arbitrary metrics and indicate the change to those metrics in a merge request. We are using the metrics report to callout changes to various artifact sizes.
We have a custom mechanism for providing feature flags, but we have begun making use of Gitlab’s feature flag mechanism. Besides an increased feature set, having them integrated into the primary development platform is rather attractive.
Another benefit has been the quality documentation. Instead of having to reverse engineer or search for external posts one can usually find an applicable example within the documentation itself.
Conclusion
After all is said and done, a few senior engineers completed the migration in under three months, after a month of building consensus, which includes regular interruption work. The migration to Gitlab and Fargate achieved our goals of having more flexibility and control over our CI/CD and has brought together all aspects of CI/CD into a single tool which provides a consistent experience and reduced cognitive load. With increased control over our production environment we have successfully broken out smaller services and deployed entirely new services.
About the Author

Jimmy Berry
Software Engineer on the Infrastructure team at Outschool.